계산 복잡도 이론
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
계산 복잡도 이론은 계산 문제의 난이도를 연구하는 이론으로, 결정 문제, 알고리즘의 계산량, 튜링 기계와 같은 계산 모델을 중심으로 다룬다. 이 이론은 문제 해결에 필요한 시간과 공간 자원을 분석하며, 점근 표기법을 사용하여 알고리즘의 효율성을 평가한다. 주요 복잡도 클래스에는 P, NP, PSPACE 등이 있으며, P-NP 문제는 이론 컴퓨터 과학의 중요한 미해결 과제 중 하나이다. NP-완전 문제는 NP에서 가장 어려운 문제로 간주되며, NP-중간 문제도 존재한다. 또한, 계산 불가능성 개념과 계산 복잡도 이론의 역사를 다룬다.
더 읽어볼만한 페이지
- 계산 복잡도 이론 - 양자 컴퓨터
양자 컴퓨터는 양자역학적 현상을 이용하여 정보를 처리하는 컴퓨터로, 큐비트를 통해 0과 1을 동시에 표현하여 특정 연산에서 기존 컴퓨터보다 빠른 속도를 보이며 암호 해독, 신약 개발 등 다양한 분야에 혁신을 가져올 것으로 기대된다. - 계산 복잡도 이론 - 선형 시간
선형 시간은 알고리즘의 실행 시간이 입력 크기에 비례하여 증가하는 것을 의미하며, O(n)의 시간 복잡도를 가지는 알고리즘 분석의 중요한 척도로 활용된다. - 수학 - 회귀 분석
회귀 분석은 종속 변수와 하나 이상의 독립 변수 간의 관계를 모델링하고 분석하는 통계적 기법으로, 최소 제곱법 개발 이후 골턴의 연구로 '회귀' 용어가 도입되어 다양한 분야에서 예측 및 인과 관계 분석에 활용된다. - 수학 - 수학적 최적화
수학적 최적화는 주어진 집합에서 실수 또는 정수 변수를 갖는 함수의 최댓값이나 최솟값을 찾는 문제로, 변수 종류, 제약 조건, 목적 함수 개수에 따라 다양한 분야로 나뉘며 여러 학문 분야에서 활용된다. - 컴퓨터에 관한 - 고속 패킷 접속
고속 패킷 접속(HSPA)은 3세대 이동통신(3G)의 데이터 전송 속도를 높이는 기술 집합체로, 고속 하향/상향 패킷 접속(HSDPA/HSUPA)을 통해 속도를 개선하고 다중 안테나, 고차 변조, 다중 주파수 대역 활용 등의 기술로 진화했으나, LTE 및 5G 기술 발전으로 현재는 상용 서비스가 중단되었다. - 컴퓨터에 관한 - 데이터베이스
데이터베이스는 여러 사용자가 공유하고 사용하는 정보의 집합으로, 데이터베이스 관리 시스템을 통해 접근하며, 검색 및 갱신 효율을 높이기 위해 고도로 구조화되어 있고, 관계형, NoSQL, NewSQL 등 다양한 모델로 발전해왔다.
2. 계산 문제와 계산량
계산 복잡도 이론에서 '문제'는 일련의 질문들의 집합이며, 각 질문은 유한한 길이의 문자열로 표현된다. 예를 들어, ''FACTORIZE'' 문제는 "이진수로 표현된 정수의 소인수를 모두 구하라"는 질문들의 집합이다. 이 문제에 속하는 개별적인 질문을 '인스턴스'라고 부르는데, "15의 소인수를 구하라"는 ''FACTORIZE'' 문제의 인스턴스이다. 외판원 순회 문제 또한 계산 문제의 한 예시이다.
알고리즘의 '계산량'은 컴퓨터가 알고리즘 실행에 필요한 계산 자원의 양을 의미하며, 알고리즘의 확장성을 나타낸다. 계산량은 주로 O 표기법을 사용하여 표현하며, 튜링 기계에서의 시간 복잡도(동작 단계 수)나 공간 복잡도(테이프 길이) 등이 있다.
- '''시간 복잡도''': 알고리즘이 문제를 해결하는 데 걸리는 단계 수를 입력 데이터 길이의 함수로 나타낸 것이다. 예를 들어, ''n''비트 입력에 대해 ''n''2 단계가 걸리는 알고리즘의 시간 복잡도는 O(''n''2)이다.
- '''공간 복잡도''': 알고리즘이 필요로 하는 기억 용량을 의미하며, O 표기법으로 나타낸다.
2. 1. 결정 문제
계산 복잡도 이론에서 다루는 계산 문제의 대부분은 결정 문제이다. 결정 문제란 답이 "예" 또는 "아니오"인 문제를 가리킨다.결정 문제는 형식 언어로 볼 수 있는데, 여기서 언어의 구성원은 출력이 '예'인 인스턴스이고, 비구성원은 출력이 '아니오'인 인스턴스이다. 목표는 알고리즘을 이용하여 주어진 입력 문자열이 고려 중인 형식 언어의 구성원인지 여부를 결정하는 것이다. 이 문제를 결정하는 알고리즘이 '예'라는 답을 반환하면 알고리즘이 입력 문자열을 받아들였다고 하고, 그렇지 않으면 거부했다고 한다.
결정 문제의 예로는 입력으로 임의의 그래프가 주어졌을 때, 주어진 그래프가 연결되어 있는지 여부를 결정하는 문제가 있다. 이 결정 문제와 관련된 형식 언어는 모든 연결 그래프의 집합이다. 이 언어의 정확한 정의를 얻으려면 그래프가 이진 문자열로 어떻게 인코딩되는지 결정해야 한다.
결정 문제를 주로 다루는 이유는 임의의 계산 문제를 어떤 결정 문제로 환원할 수 있기 때문이다. 예를 들어, `HAS-FACTOR`를 '주어진 정수 `n`과 `k`(둘 다 이진수로 주어짐)에 대해, `n`이 `k`보다 작은 소인수를 가지는가?'를 묻는 결정 문제라고 하자. 그러면 계산 문제 `FACTORIZE`(소인수분해)의 해법은 `HAS-FACTOR`를 사용하여 구현할 수 있으며, 추가적인 자원은 그다지 필요하지 않다. 구체적으로는 `k`에 대해 이분 탐색을 수행하여 `n`의 최소 소인수를 탐색하고, 그 값으로 `n`을 나눈다. 그리고 몫에 대해 다시 같은 작업을 반복하면 된다.
계산 복잡도 이론에서는 답이 "예"인지 확인하는 문제와 답이 "아니오"인지 확인하는 문제를 구분한다. "예"와 "아니오"를 뒤집은 문제를 원래 문제의 보문제라고 한다.
예를 들어, 결정 문제 `IS-PRIME`(소수 판정 문제)는 입력이 소수인 경우 "예", 그렇지 않으면 "아니오"를 반환한다. 반면, 문제 `IS-COMPOSITE`는 주어진 정수가 소수가 '''아닌'''(즉, 합성수인) 것을 결정한다. `IS-PRIME`이 "예"를 반환하면 `IS-COMPOSITE`는 "아니오"를 반환하며, 그 역도 성립한다. 따라서 `IS-COMPOSITE`는 `IS-PRIME`의 보문제이며, 마찬가지로 `IS-PRIME`은 `IS-COMPOSITE`의 보문제이다.
어떤 문제의 해를 구하는 계산량과 그 보문제의 해를 구하는 계산량은 같지만, 문제의 어떤 인스턴스에 대해 "예"가 되는 증거가 주어지고, 그 증거가 맞는지 판정하는 계산량은 같다고 할 수 없다. 예를 들어, `IS-COMPOSITE` 문제에서 어떤 정수에 대해 증거로 소인수 하나가 주어지면, 나눗셈을 통해 검산할 수 있다. 하지만 `IS-PRIME` 문제에서는 어떤 증거를 제시해야 하는지는 한동안 자명하지 않았다. 보문제를 구분하는 것은 후술하는 복잡도 클래스 NP와 co-NP 등에서 중요하게 된다.
2. 2. 계산량 측정
점근 표기법은 복잡도를 나타내는 주된 방법이다. 계산 문제의 난이도를 측정하기 위해, 최상의 알고리즘이 문제를 해결하는 데 필요한 시간을 고려한다. 실행 시간은 입력 인스턴스에 따라 달라질 수 있으며, 일반적으로 더 큰 인스턴스는 해결에 더 많은 시간이 걸린다. 따라서 문제 해결에 필요한 시간(또는 공간 등의 복잡도)은 인스턴스 크기의 함수로 계산되며, 입력 크기는 보통 비트 단위로 측정된다. 복잡도 이론은 입력 크기가 증가함에 따라 알고리즘이 어떻게 확장되는지를 연구한다.입력 크기가 일 때 걸리는 시간은 의 함수로 표현된다. 같은 크기의 서로 다른 입력에 대해 걸리는 시간이 다를 수 있으므로, 최악의 경우 시간 복잡도 은 크기 의 모든 입력에 대해 걸리는 최대 시간으로 정의된다. 이 의 다항식이면 알고리즘은 다항 시간 알고리즘이라고 한다.
최상, 최악 및 평균 사례 복잡도는 같은 크기의 서로 다른 입력에 대한 시간 복잡도(또는 다른 복잡도 척도)를 측정하는 세 가지 방법을 나타낸다.
- 최상의 경우 복잡도: 크기 의 최상의 입력에 대한 문제 해결 복잡도.
- 평균의 경우 복잡도: 문제를 평균적으로 해결하는 복잡도. 이 복잡도는 입력에 대한 확률 분포와 관련해서만 정의된다. 예를 들어, 크기가 같은 모든 입력이 동일한 확률로 나타난다고 가정하면, 평균 사례 복잡도는 크기 의 모든 입력에 대한 균일 분포와 관련하여 정의할 수 있다.
- 감가 상각 분석: 알고리즘의 전체 연산 시리즈에 걸쳐 비용이 많이 드는 연산과 비용이 적게 드는 연산을 모두 고려한다.
- 최악의 경우 복잡도: 크기 의 최악의 입력에 대한 문제 해결 복잡도.
비용이 적은 순서부터 많은 순서대로 나열하면 최상, 평균(이산 균일 분포), 감가 상각, 최악이다.
예를 들어, 결정적 정렬 알고리즘인 퀵 정렬은 정수 목록을 정렬하는 문제를 해결한다.
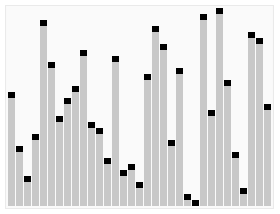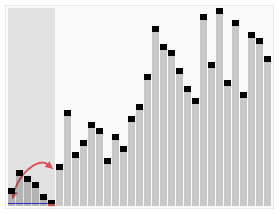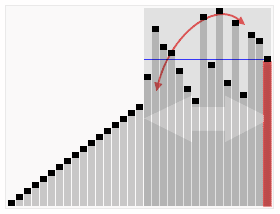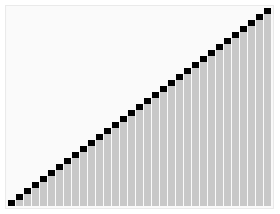
최악의 경우는 피벗이 항상 목록에서 가장 크거나 가장 작은 값일 때(따라서 목록이 절대 나뉘지 않을 때)이다. 이 경우 알고리즘은 O() 시간이 걸린다. 입력 목록의 모든 가능한 순열이 동일한 확률로 발생한다고 가정하면 정렬에 걸리는 평균 시간은 이다. 최상의 경우는 각 피벗이 목록을 반으로 나눌 때 발생하며, 이 경우에도 시간이 필요하다.
계산 시간(또는 공간 소비와 같은 유사한 자원)을 분류하기 위해, 주어진 문제를 해결하는 데 가장 효율적인 알고리즘에 필요한 최대 시간의 상한과 하한을 보이는 것이 유용하다. 특별히 명시되지 않는 한, 알고리즘의 복잡도는 일반적으로 최악의 경우 복잡도로 간주된다. 특정 알고리즘 분석은 알고리즘 분석 분야에 속한다. 문제의 시간 복잡도에 대한 상한 을 보이려면, 실행 시간이 최대 인 특정 알고리즘이 존재함을 보이기만 하면 된다. 그러나 하한을 증명하는 것은 훨씬 더 어렵다. 하한은 주어진 문제를 해결하는 모든 가능한 알고리즘에 대한 진술을 하기 때문이다. "모든 가능한 알고리즘"이라는 구절에는 오늘날 알려진 알고리즘뿐만 아니라 미래에 발견될 수 있는 모든 알고리즘이 포함된다. 문제에 대한 의 하한을 보이려면 어떤 알고리즘도 보다 낮은 시간 복잡도를 가질 수 없음을 보여야 한다.
상한과 하한은 일반적으로 상수 계수와 작은 항을 숨기는 빅 오 표기법을 사용하여 나타낸다. 이렇게 하면 경계가 사용되는 계산 모델의 특정 세부 사항과 독립적이 된다. 예를 들어, 이라면, 빅 오 표기법으로 라고 쓸 것이다.
알고리즘의 계산량은 컴퓨터가 그 알고리즘의 실행에 필요한 계산 자원의 양을 의미하며, 알고리즘의 확장성을 나타낸다. 형식적으로는 컴퓨터를 튜링 기계나 랜덤 액세스 머신(random access machine영어) 등의 계산 모델로 정식화한 후, 알고리즘이 사용하는 자원의 양을 입력 데이터 길이 등에 대한 함수로 표현한다. 계산 모델의 사소한 세부 사항에 영향을 받지 않도록, 계산량은 그 점근적인 행동에만 주목하고, 상수 배를 무시하는 O 표기법으로 나타내는 경우가 많다. 계산 모델로는 튜링 기계나 논리 회로 등이 있다. 계산 자원의 양으로는, 튜링 기계에서의 시간 복잡도(동작 단계 수)나 공간 복잡도(테이프 길이), 또 논리 회로에서의 소자 수나 깊이 등이 있다.
- 시간 복잡도는 어떤 알고리즘을 사용했을 때 문제의 인스턴스를 푸는 데 필요한 단계 수를 의미하며, 입력 데이터의 길이(비트 수 등으로 표현 가능)의 함수로 표현된다. 간단한 예로, 어떤 문제에 대한 해법이 ''n''비트의 입력에 대해 어떤 계산 모델에서 ''n''2 단계로 동작하는 경우, 시간 복잡도는 ''n''2 이지만, 다른 대부분의 계산 모델에서도 시간 복잡도는 점근적으로 상수 배의 차이만 나며, O 표기법을 사용하면 계산 모델에 관계없이 문제의 시간 복잡도를 O(''n''2)로 나타낼 수 있다. 계산을 잔디 깎는 작업에 비유하면, 그 시간 복잡도는 선형이며, 잔디밭의 면적이 2배가 되면 시간도 2배 걸린다. 이 면적이 2배가 되면 시간도 2배 걸린다는 관계는 잔디 깎는 기계의 속도와는 관계가 없다. 하지만, 사전을 이진 탐색하는 경우의 시간 복잡도는 로그 시간이며, 사전의 두께가 2배가 되어도 이진 탐색의 단계가 1 증가하는 것만으로 충분하다.
- 공간 복잡도는 유사한 개념이며, 알고리즘이 필요로 하는 기억 용량을 의미한다. 예를 들어, 종이와 펜을 사용하여 계산을 할 때 필요한 종이의 매수에 해당한다. 공간 복잡도에도 O 표기법이 사용된다.
계산 모델에 따라서는, 이것들과는 다른 계산량이 사용되는 경우도 있으며, 예를 들어 회로 복잡도가 있다. 이것은 문제의 해법을 부울 대수에 의한 논리 회로 게이트로 바꾸어, 그 회로의 규모로 계산량을 나타내는 것이다. 이것은 집적 회로의 설계 등에서 이용된다.
3. 계산 모델
알고리즘의 수행은 일반적으로 튜링 기계와 그 변종, 랜덤 액세스 머신(RAM) 등 다양한 기계 모델을 기준으로 한다.[2] 이 모델들은 추가적인 계산 능력을 제공하지 않고도 다른 모델로 변환될 수 있지만, 시간 및 메모리 소비는 다를 수 있다.[2]
비결정적 튜링 기계와 같이 특이한 자원 측면에서 분석하기 쉬운 계산 문제도 있다. 비결정적 튜링 기계는 여러 가능성을 동시에 확인하는 모델로, 비결정적 시간은 계산 문제 분석에 중요한 자원이다.
3. 1. 튜링 기계

튜링 기계는 일반적인 컴퓨팅 기계의 수학적 모델이다. 테이프의 기호를 조작하는 이론적인 장치이다. 튜링 기계는 실용적인 컴퓨팅 기술을 위해 만들어진 것이 아니라, 고급 슈퍼컴퓨터부터 연필과 종이를 사용하는 수학자에 이르기까지 모든 컴퓨팅 기계의 일반적인 모델로 사용하기 위해 만들어졌다. 어떤 문제를 알고리즘으로 해결할 수 있다면, 그 문제를 해결하는 튜링 기계가 존재한다고 본다. 이것이 처치-튜링 명제의 내용이다. RAM 기계, 컨웨이의 생명 게임, 셀룰러 오토마타, 람다 대수 또는 어떤 프로그래밍 언어에서 계산할 수 있는 모든 것은 튜링 기계에서도 계산할 수 있다. 튜링 기계는 수학적으로 분석하기 쉽고 다른 어떤 컴퓨팅 모델만큼 강력하다고 알려져 있기 때문에, 복잡도 이론에서 가장 일반적으로 사용되는 모델이다.
결정적 튜링 기계, 확률적 튜링 기계, 비결정론적 튜링 기계, 양자 튜링 기계, 대칭 튜링 기계, 교대 튜링 기계 등 여러 종류의 튜링 기계가 복잡도 클래스를 정의하는 데 사용된다. 이들은 원칙적으로 모두 동일하게 강력하지만, 시간이나 공간과 같은 자원이 제한될 때는 이들 중 일부가 다른 것보다 더 강력할 수 있다.
결정적 튜링 기계는 가장 기본적인 튜링 기계로, 앞으로 어떻게 동작할지를 결정하는 고정된 규칙 집합을 사용한다. 확률적 튜링 기계는 무작위 비트를 추가로 제공하는 결정적 튜링 기계이다. 확률적 결정을 내릴 수 있다는 점은 알고리즘이 문제를 더 효율적으로 해결하는 데 도움이 된다. 무작위 비트를 사용하는 알고리즘을 확률적 알고리즘이라고 한다. 비결정적 튜링 기계는 결정적 튜링 기계에 비결정론을 추가한 것으로, 튜링 기계가 주어진 상태에서 여러 가지 가능한 동작을 할 수 있도록 한다. 비결정론을 이해하는 한 가지 방법은 튜링 기계가 각 단계에서 여러 가능한 계산 경로로 분기되고, 이 경로 중 어느 하나에서 문제를 해결하면 문제를 해결한 것으로 간주된다는 것이다. 이 모델은 물리적으로 실현 가능한 모델이 아니며, 이론적으로 흥미로운 추상 기계일 뿐이다. 하지만, 특히 흥미로운 복잡도 클래스를 만들어낸다. 예를 들어 비결정적 알고리즘을 참고하라.
3. 2. 다른 계산 모델
표준 다중 테이프 튜링 기계 외에도 랜덤 액세스 머신 등 다양한 기계 모델들이 문헌에서 제안되었다.[2] 놀랍게도 이러한 모델들은 각각 추가적인 계산 능력을 제공하지 않고도 다른 모델로 변환될 수 있다. 이러한 대체 모델의 시간 및 메모리 소비는 다를 수 있다.[2] 이 모든 모델의 공통점은 기계가 결정적으로 동작한다는 것이다.그러나 일부 계산 문제는 더 특이한 자원 측면에서 분석하기가 더 쉽다. 예를 들어, 비결정적 튜링 기계는 한 번에 여러 가지 가능성을 확인하기 위해 분기할 수 있는 계산 모델이다. 비결정적 튜링 기계는 우리가 물리적으로 알고리즘을 계산하는 방법과는 거의 관련이 없지만, 그 분기는 우리가 분석하고자 하는 많은 수학적 모델을 정확하게 포착하므로 비결정적 시간은 계산 문제를 분석하는 데 매우 중요한 자원이다.
4. 복잡도 종류
복잡도 종류는 관련된 복잡도를 갖는 문제들의 집합이다. 더 단순한 복잡도 종류는 다음 요소들에 의해 정의된다.
- 계산 문제의 유형: 가장 일반적으로 사용되는 문제는 결정 문제이다. 하지만, 복잡도 종류는 함수 문제, 계산 문제, 최적화 문제, 약속 문제 등을 기반으로 정의될 수 있다.
- 계산 모델: 가장 일반적인 계산 모델은 결정론적 튜링 기계이지만, 많은 복잡도 종류는 비결정론적 튜링 기계, 부울 회로, 양자 튜링 기계, 단조 회로 등을 기반으로 한다.
- 제한되는 자원(또는 자원들)과 제한: "다항 시간", "로그 공간", "상수 깊이" 등.
일부 복잡도 종류는 이러한 틀에 맞지 않는 복잡한 정의를 갖기도 한다.
코밤-에드먼즈 가설은 "두 가지 합리적이고 일반적인 계산 모델의 시간 복잡도는 다항적으로 관련되어 있다"고 명시한다. 이것은 P 복잡도 종류의 기초를 형성한다.
세비치 정리에 의해 PSPACE = NPSPACE 및 EXPSPACE = NEXPSPACE임이 밝혀졌다.
다른 중요한 복잡도 클래스로는 확률적 튜링 기계를 사용하여 정의된 BPP, ZPP 및 RP, 부울 회로를 사용하여 정의된 AC 및 NC, 그리고 양자 튜링 기계를 사용하여 정의된 BQP 및 QMA가 있다. #P는 계산 문제의 중요한 복잡도 클래스이다. 대화형 증명계를 사용하여 정의된 IP 및 AM과 같은 클래스가 있다. ALL은 모든 결정 문제의 클래스이다.
시간 계층 정리와 공간 계층 정리는 각각 시간과 공간 요구 사항에 대한 질문에 답을 제공하며, 복잡도 클래스 간의 분리 결과를 도출하는 데 중요한 역할을 한다. 시간 계층 정리는 이고, 공간 계층 정리는 이다. 예를 들어, 시간 계층 정리는 P가 EXPTIME에 진정으로 포함됨을 알려주고, 공간 계층 정리는 L이 PSPACE에 진정으로 포함됨을 알려준다.
계산 복잡도 이론은 계산 가능 함수의 계산 복잡도를 다루며, 계산 가능성 이론은 문제의 해결 방법 존재 여부만을 다룬다는 점에서 차이가 있다.
계산 복잡도 이론은 “어떤 알고리즘에 대한 입력 데이터의 길이를 늘렸을 때, 실행 시간과 필요한 기억 용량은 어떻게 증가하는가?”라는 질문에 답하며, 컴퓨터의 실제적인 한계를 제시한다.
계산 복잡도 이론에서는 계산 문제와 그것을 해결하는 알고리즘을 NP, P와 같은 복잡도 클래스로 분류하고, 계산 문제가 어떤 복잡도 클래스에 속하는지 또는 속하지 않는지를 증명하거나, 클래스 간의 계층 구조를 밝히는 것을 목표로 한다. 현재 가장 중요한 과제는 P≠NP 문제의 증명이다.
계산 복잡도 이론에서 다루는 '''문제'''는 일련의 질문들의 집합이며, 각 질문은 유한 길이의 문자열로 표현되고, 주어진 질문에 대한 해답을 구하여 출력하는 계산 문제이다. 문제에 속하는 개별적인 질문을 '''인스턴스'''라고 부른다.
알고리즘의 '''계산량'''은 컴퓨터가 그 알고리즘의 실행에 필요한 계산 자원의 양을 의미하며, 알고리즘의 확장성을 나타낸다. '''시간 복잡도'''는 알고리즘을 사용했을 때 문제의 인스턴스를 푸는 데 필요한 단계 수를, '''공간 복잡도'''는 알고리즘이 필요로 하는 기억 용량을 의미한다.
계산 문제의 '''복잡도'''는 어떤 계산 모델에서 얼마나 많은 계산량의 알고리즘에 의해 풀 수 있는가로 측정된다.
계산 복잡도 이론은 계산 문제의 어려움을 다양한 계산 자원의 관점에서 분석하며, 복잡도 클래스는 특정 계산 자원을 특정 양을 사용하여 풀 수 있는 모든 계산 문제의 집합이다. 가장 많이 연구되는 계산 자원은 '''결정적 시간'''(DTIME)과 '''결정적 공간'''(DSPACE)이다. 비결정적 튜링 기계와 같이 비현실적인 양의 자원을 가정하여 계산 문제를 분석하기도 한다. 계산 복잡도 이론에서는 복잡도 척도로 계산 자원량이 다루어진다.
각 클래스에 대해 그 클래스에 속하는 문제 중에서 가장 계산하기 어려운 '''완전 문제'''를 생각할 수 있다.
4. 1. 주요 복잡도 종류
복잡도 종류는 결정론적 튜링 기계, 비결정론적 튜링 기계 등 특정 추상 기계 모델에서 특정 자원(시간 또는 공간)을 사용하여 풀 수 있는 문제들의 집합이다. 시간 복잡도와 공간 복잡도를 포괄한다.
위 표에서 ''f(n)''은 입력 크기 ''n''에 대한 함수이다.
주요 복잡도는 다음과 같다. (''p(n)''은 입력 크기 ''n''에 관한 다항식이다.)
각 복잡도 종류는 특정 튜링 기계 모델과 자원 제한 조건에 따라 정의된다. 예를 들어, P는 결정적 튜링 기계에서 다항 시간 안에 풀 수 있는 문제들의 집합이고, NP는 비결정적 튜링 기계에서 다항 시간 안에 풀 수 있는 문제들의 집합이다.
5. P-NP 문제
P-NP 문제는 이론 컴퓨터 과학 분야의 가장 중요한 미해결 문제 중 하나이다. P는 결정적 튜링 기계로 다항 시간 안에 풀 수 있는 문제들의 집합이고, NP는 비결정적 튜링 기계로 다항 시간 안에 풀 수 있는 문제들의 집합이다. P-NP 문제는 P와 NP가 같은 집합인지, 즉 모든 NP 문제를 다항 시간 안에 풀 수 있는 알고리즘이 존재하는지 묻는 문제이다.
결정적 튜링 기계는 비결정적 튜링 기계의 특수한 경우이므로 P에 속하는 모든 문제는 NP에도 속한다. 하지만 NP에 속하는 모든 문제가 P에 속하는지는 아직 밝혀지지 않았다.
P=NP 여부는 광범위한 영향을 미치기 때문에 이론 컴퓨터 과학에서 가장 중요한 미해결 문제 중 하나로 손꼽힌다.[4] 만약 P=NP라면, 운영 연구의 다양한 유형의 정수 계획법 문제, 물류의 많은 문제, 생물학의 단백질 구조 예측,[5] 순수 수학 정리의 형식적 증명을 찾는 능력 등[6] 여러 중요한 문제들에 대해 더 효율적인 해결책을 찾을 수 있다. 클레이 수학 연구소는 이 문제를 밀레니엄 문제 중 하나로 선정하고, 100만 달러의 상금을 내걸었다.[7]
코밤-에드먼즈 가설에 따르면, 복잡도 계층 P는 다항 시간 안에 풀리는 문제, 즉 '쉽게 풀리는 문제'를 수학적으로 추상화한 것이다. 반면, NP는 부울 만족 가능성 문제, 해밀턴 경로 문제, 정점 덮개 문제 등 효율적인 알고리즘이 알려지지 않은 문제들을 포함한다.
5. 1. NP-난해와 NP-완전
어떤 문제 A가 NP-난해(NP-hard)하다는 것은 NP에 속하는 모든 문제가 문제 A로 다항 시간 환원될 수 있다는 것을 의미한다.[4] NP-완전(NP-complete) 문제는 NP-난해 문제 중 NP에 속하는 문제이다.[4] 즉, NP-완전 문제는 NP에서 가장 어려운 문제라고 할 수 있다.[4] (많은 문제가 동등하게 어려울 수 있으므로 NP-완전 문제는 NP에서 가장 어려운 문제 중 하나라고 말할 수도 있다.)[4]P = NP 문제가 해결되지 않았기 때문에, 알려진 NP-완전 문제 Π₂를 다른 문제 Π₁로 환원할 수 있다면 Π₁에 대해 알려진 다항 시간 해법이 없다는 것을 나타낸다.[4] 이는 Π₁에 대한 다항 시간 해법이 Π₂에 대한 다항 시간 해법을 생성하기 때문이다.[4] 마찬가지로, 모든 NP 문제는 이 집합으로 환원될 수 있기 때문에, 다항 시간에 풀 수 있는 NP-완전 문제를 찾는 것은 P = NP를 의미한다.[4]
대표적인 NP-완전 문제로는 외판원 순회 문제, 해밀턴 경로 문제, 충족 가능성 문제(SAT) 등이 있다.
5. 2. NP-중간 문제
NP-완전에도 P에도 속하지 않는 NP 문제들을 NP-중간 문제라고 한다. 만약 P ≠ NP라면, NP-중간 문제가 존재한다는 것이 증명되었다.[3] 그래프 동형 문제, 이산 로그 문제, 정수 인수분해 문제 등이 NP-중간 문제의 후보로 거론된다. 이 문제들은 P에 속하는 것으로 알려지지도 않았고 NP-완전인 것으로 알려지지도 않은 몇 안 되는 NP 문제들이다.[30]그래프 동형 문제는 두 유한 그래프가 동형인지 판별하는 문제이다. 그래프 동형 문제가 P, NP-완전, NP-중간 중 어디에 속하는지는 아직 밝혀지지 않았지만, 적어도 NP-완전은 아닌 것으로 추정된다.[8] 만약 그래프 동형 문제가 NP-완전이라면, 다항 시간 계층은 두 번째 수준으로 붕괴된다.[9] 다항 시간 계층이 특정 수준으로 붕괴되지 않는다고 널리 받아들여지기 때문에, 그래프 동형 문제는 NP-완전이 아니라고 추정된다. 바바이 라슬로와 유진 룩스가 제시한 알고리즘은 n개의 꼭짓점을 가진 그래프에 대해 의 실행 시간을 갖는다.[10]
정수 인수분해 문제는 주어진 정수의 소인수분해를 찾는 문제이다. 이를 결정 문제 형태로 표현하면, 입력값이 k보다 작은 소인수를 갖는지 판별하는 문제가 된다. 아직 효율적인 정수 인수분해 알고리즘은 알려져 있지 않으며, 이는 RSA 암호 시스템 등 여러 현대 암호 시스템의 기반이 된다. 정수 인수분해 문제는 NP와 co-NP에 속한다.[11] 만약 이 문제가 NP-완전이라면, 다항 시간 계층은 첫 번째 수준으로 붕괴된다. 정수 인수분해에 대해 알려진 가장 효율적인 알고리즘은 일반 수체 체이며, 홀수 정수 n을 인수분해하는 데 의 시간이 걸린다.[12] 그러나 양자 알고리즘인 쇼어 알고리즘은 다항 시간 안에 정수 인수분해 문제를 해결할 수 있다.
6. 계산 불가능성
이론적으로는 해결할 수 있지만, 그렇게 하기 위해서는 비현실적이고 유한한 자원(예: 시간)이 필요한 문제는 '''계산 불가능한 문제'''라고 한다.[14] 반대로, 실제로 해결할 수 있는 문제는 '''계산 가능한 문제'''라고 한다.[14]
계산 가능한 문제는 종종 다항 시간 해법을 가진 문제(, )로 식별된다. 이것을 코브햄-에드먼즈 가설이라고 한다. 이러한 의미에서 계산 불가능한 것으로 알려진 문제에는 EXPTIME-난해 문제가 포함된다. 만약 가 와 같지 않다면, NP-난해 문제도 이러한 의미에서 계산 불가능하다.
하지만 이러한 식별은 정확하지 않다. 차수가 크거나 선행 계수가 큰 다항 시간 해법은 빠르게 증가하며, 실제 크기의 문제에는 비현실적일 수 있다. 반대로, 느리게 증가하는 지수 시간 해법은 현실적인 입력에 대해 실용적일 수 있거나, 최악의 경우 오랜 시간이 걸리는 해법이 대부분의 경우 또는 평균적인 경우에는 짧은 시간이 걸릴 수 있으므로 여전히 실용적일 수 있다.
지수 시간 알고리즘이 일반적으로 실제로 사용할 수 없는 이유를 확인하려면, 정지하기 전에 번의 연산을 수행하는 프로그램을 고려해 보자. 작은 (예: 100)에 대해, 그리고 예를 들어 컴퓨터가 초당 번의 연산을 수행한다고 가정하면, 프로그램은 약 년 동안 실행되며, 이것은 우주의 나이와 같은 정도의 크기이다.
7. 역사
가브리엘 라메(Gabriel Lamé)가 1844년에 유클리드 알고리즘의 실행 시간을 분석한 것은 알고리즘 복잡도 분석의 초기 사례 중 하나이다.[20]
앨런 튜링(Alan Turing)이 1936년에 정의한 튜링 기계는 컴퓨터의 단순화된 모델로, 알고리즘 문제 복잡도 연구의 기반을 마련하는 데 중요한 역할을 했다.
계산 복잡도에 대한 체계적인 연구는 1965년 주리스 하르트마니스(Juris Hartmanis)와 리처드 E. 스턴스(Richard E. Stearns)의 논문 "On the Computational Complexity of Algorithms"에서 시작되었다. 이 논문에서는 시간 복잡도와 공간 복잡도의 정의를 제시하고 계층 정리(hierarchy theorems)를 증명했다.[20] 같은 해, 잭 에드먼즈(Jack Edmonds)는 입력 크기의 다항식으로 실행 시간이 제한되는 알고리즘을 "좋은" 알고리즘으로 간주할 것을 제안했다.[21]
존 마이힐(John Myhill)의 선형 제한 오토마타(linear bounded automata)(1960), 레이먼드 스멀리안(Raymond Smullyan)의 기본 집합(rudimentary sets) 연구(1961), 히사오 야마다(Hisao Yamada)의 실시간 계산(real-time computations)에 관한 논문(1962) 등은 제한된 자원을 가진 튜링 기계로 풀 수 있는 문제를 연구한 초기 논문들이다.[20][22] 보리스 트라크텐브로트(Boris Trakhtenbrot)(1956)는 이보다 앞서 다른 특정 복잡도 척도를 연구했다.[23]
1967년 마누엘 블룸(Manuel Blum)은 블룸 공리(Blum axioms)로 알려진 계산 가능한 함수 집합에 대한 복잡도 척도의 바람직한 속성을 명시하는 공리를 공식화하고, 속도 향상 정리를 증명했다.
1971년 스티븐 쿡(Stephen Cook)과 레오니드 레빈(Leonid Levin)이 증명한 NP-완전 문제의 존재는 이 분야를 크게 발전시켰다. 1972년 리처드 카프(Richard Karp)는 21가지 조합론적 및 그래프 이론적 문제가 NP-완전임을 보이며 이 아이디어를 더욱 발전시켰다.[25]
8. 주요 연구자
참조
[1]
웹사이트
P vs NP Problem
http://www.claymath.[...]
2018-07-06
[2]
문서
Chapter 1: The computational model and why it doesn't matter
2009
[3]
논문
On the structure of polynomial time reducibility
[4]
문서
Chapter 7: Time complexity
2006
[5]
논문
Protein folding in the hydrophobic-hydrophilic (HP) model is NP-complete
[6]
웹사이트
The P versus NP Problem
http://www.claymath.[...]
Clay Mathematics Institute
2000-04-00
[7]
논문
The Millennium Grand Challenge in Mathematics
https://www.ams.org/[...]
[8]
논문
Graph isomorphism is in SPP
[9]
논문
Graph Isomorphism is in the Low Hierarchy
[10]
논문
Graph Isomorphism in Quasipolynomial Time
2016
[11]
웹사이트
Computational Complexity Blog: Factoring
http://weblog.fortno[...]
2002-09-13
[12]
웹사이트
Number Field Sieve
http://mathworld.wol[...]
[13]
웹사이트
Boaz Barak's course on Computational Complexity
http://www.cs.prince[...]
[14]
서적
Introduction to Automata Theory, Languages, and Computation
Addison Wesley
[15]
서적
Algorithms and Complexity
https://books.google[...]
Elsevier
[16]
서적
Writing for Computer Science
https://books.google[...]
Springer
[17]
논문
Complexity Theory and Numerical Analysis
Cambridge Univ Press
[18]
논문
A Survey on Continuous Time Computations
[19]
논문
Computational Techniques for the Verification of Hybrid Systems
2003-07-00
[20]
문서
[21]
간행물
Combinatorics, Complexity, and Randomness
http://cecas.clemson[...]
[22]
논문
Real-Time Computation and Recursive Functions Not Real-Time Computable
[23]
논문
Signalizing functions and tabular operators
[24]
서적
From Logic to Theoretical Computer Science – An Update
https://books.google[...]
Springer
[25]
논문
Reducibility Among Combinatorial Problems
New York: Plenum
[26]
서적
Introduction to the Theory of Computation
Thomson Course Technology
2006
[27]
논문
Protein folding in the hydrophobic-hydrophilic (HP) model is NP-complete
http://www.ncbi.nlm.[...]
1998
[28]
논문
The P versus NP Problem
http://www.claymath.[...]
クレイ数学研究所
2000-04-00
[29]
논문
The Millennium Grand Challenge in Mathematics
http://www.ams.org/n[...]
[30]
서적
Theory of Computational Complexity
John Wiley & Sons
2000
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com